Four months ago, we released Moonlight, validating the effectiveness of the Muon optimizer on a 16B MoE model. In Moonlight, we confirmed the necessity of adding Weight Decay to Muon and proposed a technique for migrating Adam hyperparameters through Update RMS alignment, enabling Muon to be quickly applied to LLM training. However, when we attempted to further scale Muon to models with hundreds of billions of parameters, we encountered a new "roadblock" — MaxLogit explosion.
To address this issue, we propose a simple yet extremely effective new method we call "QK-Clip." This method approaches and solves the MaxLogit phenomenon from a fundamental perspective while preserving model performance. It has become one of the key training technologies for our latest released trillion-parameter model "Kimi K2."
Problem Description#
The "Logit" in "MaxLogit explosion" refers to the Attention matrix before Softmax, i.e., $\boldsymbol{Q}\boldsymbol{K}^{\top}$, and MaxLogit refers to the maximum value of all Logits, which we denote as $S_{\max} = \max_{i,j}\, \boldsymbol{q}_i\cdot \boldsymbol{k}_j$.
MaxLogit explosion refers to the phenomenon where $S_{\max}$ continues to increase linearly or even super-linearly as training progresses, showing no signs of stabilization for a considerable period.
Let's briefly introduce the MaxLogit explosion phenomenon. Recall the definition of Attention:
Here we omit the scaling factor $1/\sqrt{d}$ since it can always be absorbed into the definitions of $\boldsymbol{Q}$ and $\boldsymbol{K}$. The "Logit" in "MaxLogit explosion" refers to the Attention matrix before Softmax, i.e., $\boldsymbol{Q}\boldsymbol{K}^{\top}$, and MaxLogit refers to the maximum value of all Logits, which we denote as:
Here, $\max$ should also be taken over the batch_size dimension, ultimately yielding a scalar. MaxLogit explosion refers to the phenomenon where $S_{\max}$ continues to increase linearly or even super-linearly as training progresses, showing no signs of stabilization for a considerable period.
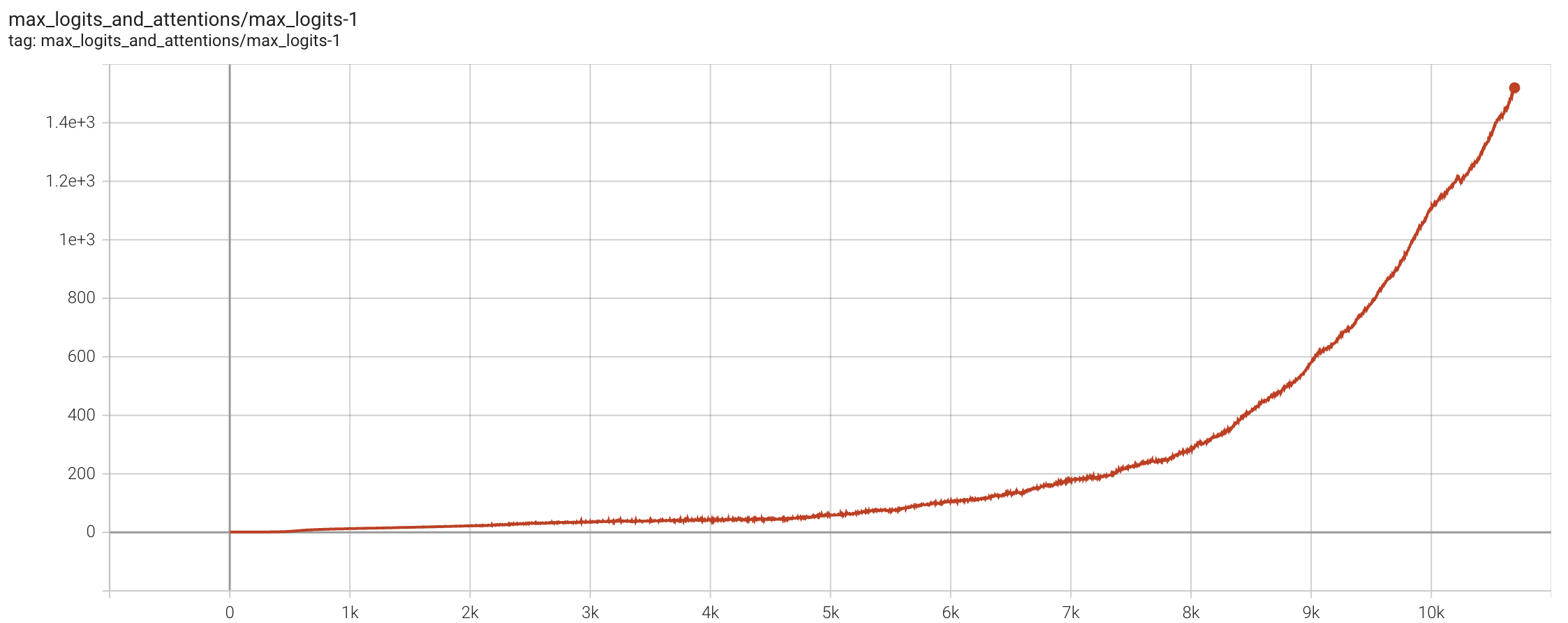
MaxLogit Explosion Phenomenon
MaxLogit is essentially an outlier indicator. Its explosion means that outliers have exceeded controllable bounds. Specifically, we have:
Since $\boldsymbol{x}$ typically undergoes RMSNorm, $\Vert\boldsymbol{x}_i\Vert \Vert\boldsymbol{x}_j\Vert$ generally does not explode. Therefore, MaxLogit explosion implies that the spectral norms $\Vert\boldsymbol{W}_q\Vert,\Vert\boldsymbol{W}_k\Vert$ risk diverging to infinity, which is clearly undesirable.
Since any large value becomes less than 1 after Softmax, in fortunate cases this phenomenon may not cause severe consequences beyond wasting an Attention Head. However, in worse scenarios, it may lead to Gradient Spikes or even training collapse. Therefore, it is prudent to avoid MaxLogit explosion whenever possible.
Previous Attempts#
In "Muon Sequel: Why Did We Choose to Experiment with Muon?" we briefly analyzed that Weight Decay can to some extent prevent MaxLogit explosion, so small models rarely experience it. Even in a 16B model like Moonlight, MaxLogit rises to around 120 before automatically decreasing.
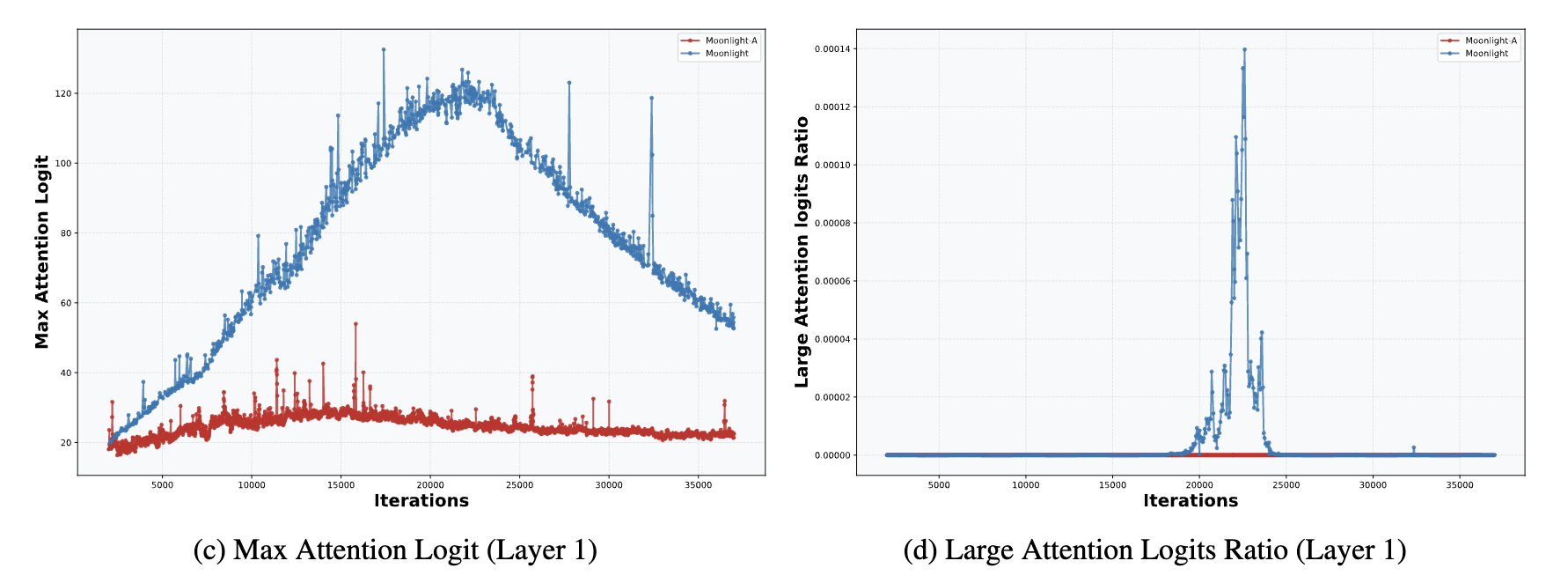
Moonlight's MaxLogit Automatically Decreases
In other words, MaxLogit explosion primarily occurs in very large parameter models. The larger the model, the more training instability factors emerge, making it harder for Weight Decay to stabilize training. While increasing Weight Decay can enhance control, it also leads to significant performance degradation, making this approach impractical.
Another direct approach is to apply $\text{softcap}$ directly to Logits:
where $\text{softcap}(x;\tau) = \tau\tanh(x/\tau)$, introduced by Google's Gemma2. Due to the boundedness of $\tanh$, $\text{softcap}$ naturally ensures bounded Logits after application, but it cannot guarantee boundedness before $\text{softcap}$ (empirically verified). Thus, $\text{softcap}$ merely transforms one problem into another without actually solving it.
Perhaps Google itself recognized this issue, as later Gemma3 abandoned $\text{softcap}$ in favor of "QK-Norm":
QK-Norm is indeed an effective method for suppressing MaxLogit. However, it is only applicable to MHA, GQA, etc., and not to MLA, because QK-Norm requires materializing $\boldsymbol{Q}$ and $\boldsymbol{K}$, but for MLA, the training-phase $\boldsymbol{Q}$ and $\boldsymbol{K}$ differ from those in the decoding phase (as shown below). During decoding, we cannot fully materialize the training-phase $\boldsymbol{K}$; in other words, QK-Norm cannot be applied during decoding.
| Training / Prefill | Decoding |
|---|---|
| \[ \begin{aligned} \boldsymbol{o}_t &= \left[\boldsymbol{o}_t^{(1)}, \boldsymbol{o}_t^{(2)}, \cdots, \boldsymbol{o}_t^{(h)}\right] \\[10pt] \boldsymbol{o}_t^{(s)} &= \frac{\sum_{i\leq t}\exp\left(\boldsymbol{q}_t^{(s)} \boldsymbol{k}_i^{(s)}{}^{\top}\right)\boldsymbol{v}_i^{(s)}}{\sum_{i\leq t}\exp\left(\boldsymbol{q}_t^{(s)} \boldsymbol{k}_i^{(s)}{}^{\top}\right)} \\[15pt] \boldsymbol{q}_i^{(s)} &= \left[\boldsymbol{x}_i\boldsymbol{W}_{qc}^{(s)},\boldsymbol{x}_i\boldsymbol{W}_{qr}^{(s)}\color{#3ce2f7}{\boldsymbol{\mathcal{R}}_i}\right]\in\mathbb{R}^{d_k + d_r}\\[5pt] \boldsymbol{k}_i^{(s)} &= \left[\boldsymbol{c}_i\boldsymbol{W}_{kc}^{(s)},\boldsymbol{x}_i\boldsymbol{W}_{kr}^{(s)}\color{#3ce2f7}{\boldsymbol{\mathcal{R}}_i}\right]\in\mathbb{R}^{d_k + d_r} \\[5pt] \boldsymbol{v}_i^{(s)} &= \boldsymbol{c}_i\boldsymbol{W}_v^{(s)}\in\mathbb{R}^{d_v}\\[5pt] \boldsymbol{c}_i &= \boldsymbol{x}_i \boldsymbol{W}_c\in\mathbb{R}^{d_c} \end{aligned} \] | \[ \begin{aligned} \boldsymbol{o}_t &= \left[\boldsymbol{o}_t^{(1)}\boldsymbol{W}_v^{(1)}, \boldsymbol{o}_t^{(2)}\boldsymbol{W}_v^{(2)}, \cdots, \boldsymbol{o}_t^{(h)}\boldsymbol{W}_v^{(h)}\right] \\[10pt] \boldsymbol{o}_t^{(s)} &= \frac{\sum_{i\leq t}\exp\left(\boldsymbol{q}_t^{(s)} \boldsymbol{k}_i{}^{\top}\right)\boldsymbol{v}_i}{\sum_{i\leq t}\exp\left(\boldsymbol{q}_t^{(s)} \boldsymbol{k}_i{}^{\top}\right)} \\[15pt] \boldsymbol{q}_i^{(s)} &= \left[\boldsymbol{x}_i\boldsymbol{W}_{qc}^{(s)}\boldsymbol{W}_{kc}^{(s)}{}^{\top}, \boldsymbol{x}_i\boldsymbol{W}_{qr}^{(s)}\color{#3ce2f7}{\boldsymbol{\mathcal{R}}_i}\right]\in\mathbb{R}^{d_c + d_r}\\[5pt] \boldsymbol{k}_i &= \left[\boldsymbol{c}_i, \boldsymbol{x}_i\boldsymbol{W}_{kr}\color{#3ce2f7}{\boldsymbol{\mathcal{R}}_i}\right]\in\mathbb{R}^{d_c + d_r}\\[5pt] \boldsymbol{v}_i &= \boldsymbol{c}_i = \boldsymbol{x}_i \boldsymbol{W}_c\in\mathbb{R}^{d_c} \end{aligned} \] |
Why use MLA? We have discussed this in two articles: "Transformer Upgrade Path 21: What Makes MLA Good? (Part 1)" and "Transformer Upgrade Path 21: What Makes MLA Good? (Part 2)", and will not repeat it here. In summary, we desire a method similar to QK-Norm that can guarantee MaxLogit suppression for MLA.
Direct Approach#
After multiple failed attempts with indirect methods, we realized that the most direct solution to guarantee resolution of MaxLogit explosion would be to use MaxLogit itself as the trigger signal for scaling.
During this period, we also tried some indirect methods, such as separately reducing the learning rate for $\boldsymbol{Q},\boldsymbol{K}$, increasing their Weight Decay individually, etc., but none were effective. The closest to success was Partial QK-Norm. For MLA, its $\boldsymbol{Q},\boldsymbol{K}$ are divided into qr, qc, kr, kc four parts, of which the first three can be materialized during decoding. Thus, we applied RMSNorm to these three parts, which successfully suppressed MaxLogit but severely degraded length activation performance.
After multiple failures, we began to reflect: our previous attempts were merely "indirect means" to suppress MaxLogit. What is the direct method that guarantees solving MaxLogit explosion? From inequality Equation (3) we can easily consider performing singular value clipping on $\boldsymbol{W}_q,\boldsymbol{W}_k$, but this is still an indirect approach, and the computational cost of singular value clipping is not trivial.
However, it is clear that post-hoc scaling of $\boldsymbol{W}_q,\boldsymbol{W}_k$ is theoretically feasible. The questions are when to scale and by how much. Finally, in a moment of insight, the author realized: MaxLogit itself is the most direct signal to trigger scaling! Specifically, when MaxLogit exceeds the desired threshold $\tau$, we directly multiply $\boldsymbol{Q}\boldsymbol{K}^{\top}$ by $\gamma = \tau / S_{\max}$, ensuring the new MaxLogit does not exceed $\tau$. The multiplication by $\gamma$ can be absorbed into the weights of $\boldsymbol{Q}$ and $\boldsymbol{K}$, yielding the initial version of QK-Clip:
1: # Initialization
2: threshold τ = 100 # Desired MaxLogit threshold
3:
4: # For each training step
5: W_t = Optimizer(W_{t-1}, G_t) # Standard optimizer update
6:
7: # QK-Clip operation
8: for each layer l:
9: S_max = max_{i,j} q_i · k_j # Compute MaxLogit
10: if S_max > τ:
11: γ = sqrt(τ / S_max) # Clip factor
12: for W in {W_q^{(l)}, W_k^{(l)}}:
13: W_t ← W_t × γ
where $S_{\max}^{(l)}$ is the MaxLogit of the $l$-th layer Attention, and $\boldsymbol{W}_q^{(l)}, \boldsymbol{W}_k^{(l)}$ are the corresponding $\boldsymbol{Q},\boldsymbol{K}$ weights. In other words, after the optimizer update, we decide whether to clip the $\boldsymbol{Q},\boldsymbol{K}$ weights based on the magnitude of $S_{\max}^{(l)}$, with the clipping magnitude directly determined by the ratio between $S_{\max}^{(l)}$ and threshold $\tau$, ensuring that the clipped matrix no longer exhibits MaxLogit explosion. Since this directly operates on weights, it does not affect inference mode and is naturally compatible with MLA.
Refined Adjustment#
The initial QK-Clip successfully suppressed MaxLogit in MLA, but upon closer inspection of the model's "internal state," we discovered it suffered from "over-clipping." Fixing this issue yields the final version of QK-Clip.
We know that regardless of the Attention variant, there are multiple heads. Initially, we monitored only one MaxLogit metric per Attention layer, with Logits from all heads combined when taking the maximum. This caused QK-Clip to clip all heads together. However, when we monitored MaxLogit per head separately, we found that actually only a few heads per layer exhibited MaxLogit explosion. Clipping all heads by the same ratio meant most heads were "innocently affected," which is what over-clipping entails.
The QK-Clip operation multiplies by a number less than 1. For heads with MaxLogit explosion, this exactly counteracts the growth trend. However, for other heads, it is merely a reduction (they have no or weak growth trends). Being multiplied by a number less than 1 over time can easily cause them to approach zero, which is the manifestation of "over-clipping."
Therefore, to avoid "harming the innocent," we should monitor MaxLogit and apply QK-Clip per head. However, this hides another subtle detail: the initial QK-Clip distributed the clip factor equally to $\boldsymbol{Q}$ and $\boldsymbol{K}$. But MLA's $\boldsymbol{Q},\boldsymbol{K}$ have four parts: qr, qc, kr, kc, where kr is shared across all heads. Clipping it would similarly cause "harming the innocent." Therefore, for (qr, kr), we should only clip qr.
After these adjustments, the final QK-Clip becomes:
1: # Final QK-Clip with per-head clipping
2: threshold τ = 100 # Desired MaxLogit threshold
3:
4: # For each training step
5: W_t = Optimizer(W_{t-1}, G_t)
6:
7: # Per-head QK-Clip operation
8: for each layer l, each head h:
9: S_max = max_{i,j} q_i^{(h)} · k_j^{(h)} # Compute MaxLogit for head h
10: if S_max > τ:
11: # For qc and kc components
12: for W in {W_{qc}^{(l,h)}, W_{kc}^{(l,h)}}:
13: W_t ← W_t × sqrt(τ / S_max)
14: # For qr component only
15: for W in {W_{qr}^{(l,h)}}:
16: W_t ← W_t × (τ / S_max)
where superscript ${}^{(l,h)}$ denotes the $l$-th layer, $h$-th head.
Scaling Path#
At this point, the operational details of QK-Clip have been fully introduced. It directly uses the desired MaxLogit as a signal to make minimal modifications to the $\boldsymbol{Q},\boldsymbol{K}$ weights, achieving the effect of controlling MaxLogit values within a specified threshold. Since this method directly modifies weights, it has better compatibility than QK-Norm and can be used with MLA.
In training Kimi K2, we set threshold $\tau$ to 100. Total training steps were approximately 220k. Starting from around 7k steps, heads with MaxLogit exceeding $\tau$ began to appear. For a considerable period thereafter, Muon Update and QK-Clip engaged in a "tug-of-war": Muon attempting to increase MaxLogit while QK-Clip attempting to decrease it, maintaining a delicate balance. Interestingly, after 70k steps, all heads' MaxLogit actively decreased below 100, and QK-Clip ceased to activate.
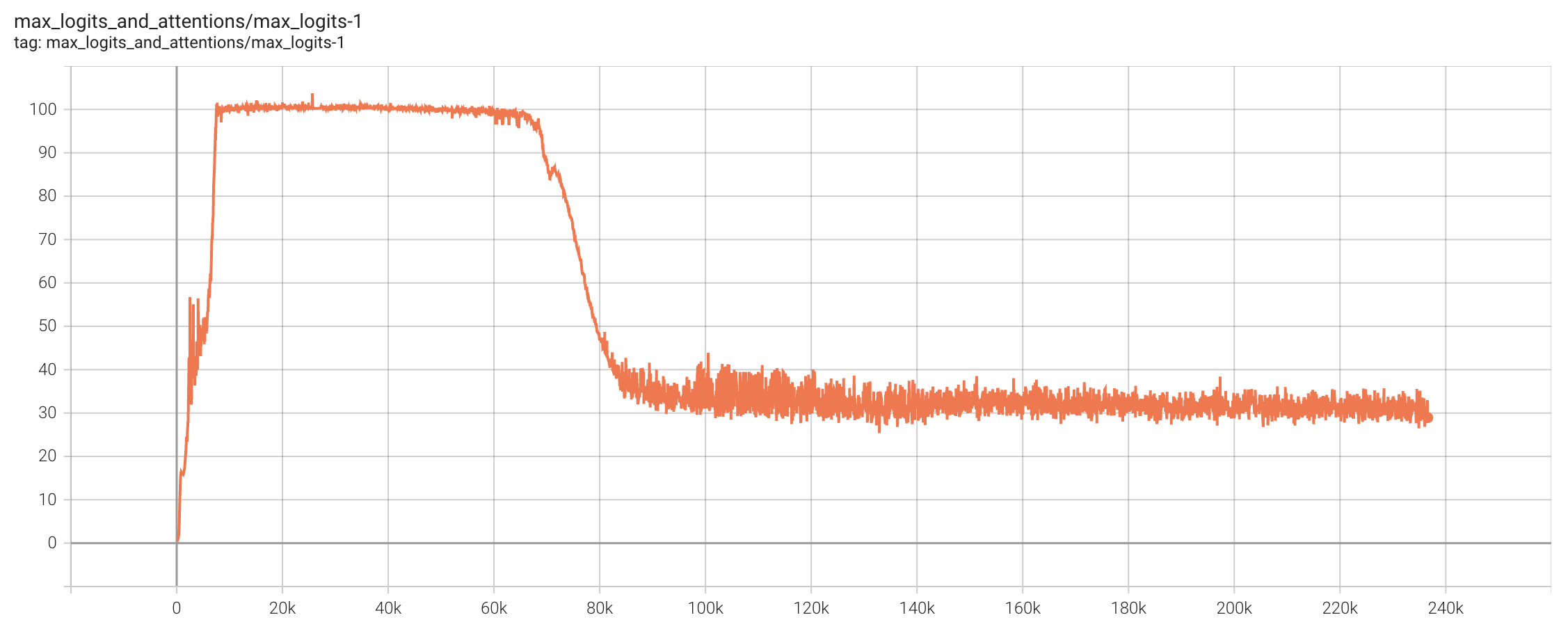
After nearly 70k steps of tug-of-war between Muon and QK-Clip, MaxLogit actively decreases
This indicates that under Weight Decay, as long as we can stabilize training, models will likely actively reduce MaxLogit eventually. QK-Clip's role is precisely to help models navigate the early training phase more smoothly. Some readers may worry that QK-Clip harms performance, but we conducted comparative experiments on small models: even when suppressing MaxLogit to particularly low values (e.g., 30) via QK-Clip, we observed no substantial performance difference. Combined with the phenomenon that models actively reduce MaxLogit in later stages, we have reason to believe QK-Clip is lossless to performance.
We also observed in experiments that Muon generally causes MaxLogit explosion more easily than Adam. Thus, to some extent, QK-Clip is a supplementary update rule specifically for Muon, serving as one of Muon's "secret techniques" for ultra-large-scale training, which is the meaning of this article's title. Accordingly, we combined the Muon modifications from our Moonlight with QK-Clip, naming it "MuonClip" ($\boldsymbol{W}\in\mathbb{R}^{n\times m}$):
Note: "Muon generally causes MaxLogit explosion more easily than Adam" does not imply only Muon suffers from MaxLogit explosion. We know DeepSeek-V3 was trained with Adam, and we observed MaxLogit explosion in its open-source model. Similarly, Gemma2 used $\text{softcap}$ to prevent MaxLogit explosion, which was also Adam-trained. Therefore, while we emphasize QK-Clip's value for Muon, if readers insist on using Adam, it can also be combined with Adam to form AdamClip.
Theoretical Analysis#
Why does Muon more easily cause MaxLogit explosion? This section attempts to provide a theoretical explanation for reference.
From inequality Equation (3), MaxLogit explosion often indicates that the spectral norms of $\boldsymbol{W}_q$ or $\boldsymbol{W}_k$ show signs of explosion. Indeed, the definition of spectral norm also involves a $\max$ operation; the two are essentially connected. Therefore, the problem can be transformed into "why Muon more easily causes spectral norm explosion." We know spectral norm equals the largest singular value, so we can further consider "why Muon tends to increase singular values."
What distinguishes Muon from Adam? Muon's update quantity undergoes $\msign$ operation, where all singular values are equal, meaning its effective rank is full rank; whereas under normal circumstances, matrices typically have singular values of varying sizes dominated by the first few, making them low-rank from an effective rank perspective—an assumption we also apply to Adam's update quantity. This assumption is not novel; for example, higher-order MuP similarly assumes low-rankness of Adam updates.
Formally, let the SVD of parameter $\boldsymbol{W}_{t-1}$ be $\sum_i \sigma_i \boldsymbol{u}_i \boldsymbol{v}_i^{\top}$, Muon's update SVD be $\sum_j \bar{\sigma}\bar{\boldsymbol{u}}_j \bar{\boldsymbol{v}}_j^{\top}$, and Adam's update SVD be $\sum_j \tilde{\sigma}_j\tilde{\boldsymbol{u}}_j \tilde{\boldsymbol{v}}_j^{\top}$. Then:
Clearly, if singular vector pair $\boldsymbol{u}_i \boldsymbol{v}_i^{\top}$ closely aligns with some $\bar{\boldsymbol{u}}_j \bar{\boldsymbol{v}}_j^{\top}$ or $\tilde{\boldsymbol{u}}_j \tilde{\boldsymbol{v}}_j^{\top}$, they will directly add up, increasing $\boldsymbol{W}_t$'s singular values. Since Muon's update is full-rank, its "collision probability" with $\boldsymbol{W}_{t-1}$ is much higher than Adam's, making Muon more prone to increasing parameter singular values.
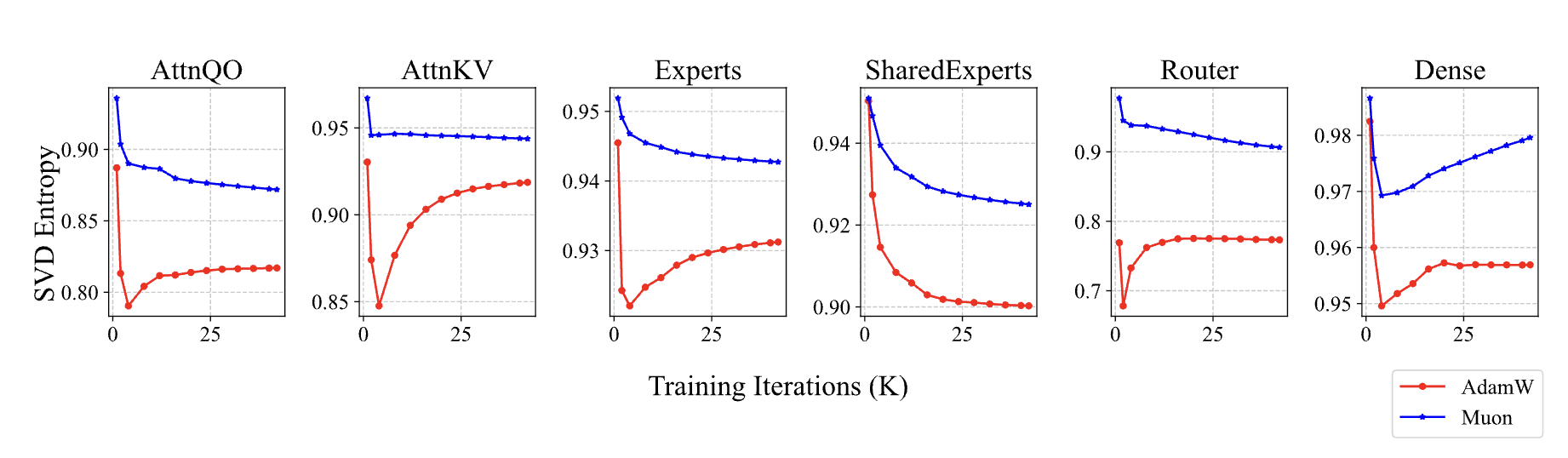
Singular value entropy (equivalent to effective rank) comparison between Muon and Adam trained model weights
Of course, this analysis is general, not limited to $\boldsymbol{Q},\boldsymbol{K}$ weights. Indeed, in Moonlight we already verified that model weights trained with Muon generally have higher singular value entropy, corroborating this hypothesis. The special aspect of Attention Logit is that it is a bilinear form $\boldsymbol{q}_i\cdot \boldsymbol{k}_j = (\boldsymbol{x}_i \boldsymbol{W}_q)\cdot(\boldsymbol{x}_j \boldsymbol{W}_k)$, where the multiplication of $\boldsymbol{W}_q,\boldsymbol{W}_k$ increases explosion risk and can lead to a vicious cycle of "worsening the worse," ultimately causing MaxLogit explosion.
Lastly, "Muon's collision probability is much higher than Adam's" is relative; collisions of singular vectors remain low-probability events, explaining why only a few Attention Heads exhibit MaxLogit explosion.
This perspective can also explain a previous Moonlight observation: models pre-trained with Muon/Adam and then fine-tuned with Adam/Muon typically yield suboptimal results. Because Muon-trained weights have higher effective rank, while Adam's updates are low-rank, the mismatch reduces fine-tuning efficiency; conversely, Adam-trained weights have lower effective rank, but Muon's updates are full-rank, more likely to interfere with small singular value components, causing the model to deviate from the pre-trained low-rank local optimum, affecting fine-tuning efficiency.
Extensions#
At this point, the important computational and experimental details about QK-Clip should be clear. Additionally, it is worth noting that while QK-Clip's concept is simple, implementing it with per-head clipping in distributed training is slightly challenging, as parameter matrices are often fragmented across devices (modifying on Muon's basis is not difficult, but slightly more complex on Adam's basis).
Key Insight: For our team, QK-Clip is not merely a specific method to solve MaxLogit explosion but also represents an "epiphany" after repeatedly attempting and failing with indirect approaches: With a clear metric, we should seek direct solutions that guarantee problem resolution, rather than wasting time on approaches like reducing LR, increasing Weight Decay, or partial QK-Norm that may but do not necessarily solve the problem.
Methodologically, QK-Clip's approach is not limited to solving MaxLogit explosion; it can be considered an "antibiotic" for many training instability problems. By antibiotic, we mean it may not be the most elegant solution but is often one of the most direct and effective methods. QK-Clip possesses this characteristic and can be generalized to "clip where unstable."
For example, in some cases models may experience "MaxOutput explosion." We could consider clipping the $\boldsymbol{W}_o$ weights based on MaxOutput values. Analogous to QK-Clip's per-head operation, we would need to consider per-dimension clipping, but per-dimension clip cost is obviously high, potentially requiring compromise. In summary, "clip where unstable" provides a unified solution framework, but specific details depend on implementation.
Finally, QK-Clip's operation of manually formulating update rules based on certain signals was partly inspired by DeepSeek's Loss-Free load balancing strategy—here we pay tribute to DeepSeek once again!
Summary#
This paper proposes QK-Clip, a novel approach to the MaxLogit explosion problem. Unlike QK-Norm, it is a post-hoc adjustment scheme for Q and K weights that does not alter forward computation, thus having broader applicability. It is a crucial stabilization strategy for the "Muon + MLA" combination in ultra-large-scale training and one of the key technologies in our latest released trillion-parameter model Kimi K2.
Original Article: Su Jianlin. QK-Clip: Enabling Muon to Further Advance in Scale-up. Scientific Spaces.
How to cite this translation:
BibTeX: